概要
ハイパーパラメータのチューニングめんどくさくないですか?
ということで、機械学習モデル作成の際に避けては通れないハイパーパラメータのチューニングを自動化するツール、「optuna」を利用してみました。
kaggleなどでも一般的になってきているツールなので使えるに越したことはなさそうです。
optunaとは
クソ適当に箇条書きします。
- 機械学習モデルのハイパーパラメータ自動最適化フレームワークだよ
- 株式会社Preferred Networksが開発したMade in Japanのフレームワークだよ
- 最適化したいパラメータとパラメータの範囲を決めておけば、範囲内のパラメータの最適値を探索してくれるすごいやつだよ
- ベイズ最適化を利用してるらしいよ
公式リファレンスは下記を参照ください。
21/6/11 追記
想像以上に多くの方に読まれてるので、ソースコード公開します。
githubにしようかと思いましたが、kaggleの公開Codeに載せたのでこちらをご参照ください。

使ってみた
利用するデータセット
利用するデータセットは以前記事にした、kaggleのMNISTデータセットを利用したDigit Recognizerのコンペのデータを利用して、CNNのパラメータ最適化を実施したいと思います。

下記に前回の記事を載せときます。この時はパラメータのことを考えないまま適当にモデル作ったので、どれだけ精度向上が見込めるか期待です。

データインポート&前処理
データインポート、前処理については、過去の記事と同様の処理を行います。
割愛しようかと思いましたが、念のため。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#データインポート import pandas as pd import numpy as np from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt train = pd.read_csv('../input/digit-recognizer/train.csv') test = pd.read_csv('../input/digit-recognizer/test.csv') # 教師データ、テストデータに分類して、float型に変換する。 X_train = (train.iloc[:,1:].values).astype('float32') y_train = train.iloc[:,0].values X_test = test.values.astype('float32') #精度確認のため、教師データをさらに教師データ、テストデータに分割 X_train2, X_test2, y_train2, y_test2 = train_test_split(X_train, y_train, test_size = 0.2, train_size = 0.8, stratify = y_train) #データreshape(28×28の行列に変換) img_rows, img_cols = 28, 28 num_classes = 10 X_train2 = X_train2.reshape(X_train2.shape[0], img_rows, img_cols, 1) X_test2 = X_test2.reshape(X_test2.shape[0], img_rows, img_cols, 1) #y_trainのデータをto_categoricalで2値クラスの行列へ変換 y_train2 = keras.utils.to_categorical(y_train2, num_classes) |
最適化するパラメータの範囲を決定
ここから本題のoptunaを使ってみます。
前回のモデルを参考にモデルを構築しますが、最適化したいパラメータを変数にしておきます。
- 畳み込み層の深さ(num_layer)
- 各畳み込み層のフィルターの形状(num_filters)
- 全結合層のノード数(mid_units)
- Dropout率(dropout_rate)
- 最適化手法(optimizer)
前回の記事では畳み込み層2層のモデルであったので、もう少し層を深くした方が精度が上がるのではないかと思ってます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import optuna import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D img_rows, img_cols = 28, 28 num_classes = 10 #CNNモデルの定義 def create_model(num_layer, mid_units, num_filters,dropout_rate): model = Sequential() model.add(Conv2D(filters=num_filters[0], kernel_size=(3, 3), activation="relu", input_shape=(img_rows, img_cols, 1))) for i in range(1,num_layer): model.add(Conv2D(filters=num_filters[i], kernel_size=(3,3), padding="same", activation="relu")) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(dropout_rate)) model.add(Flatten()) model.add(Dense(mid_units)) model.add(Dropout(dropout_rate)) model.add(Dense(num_classes, activation='softmax')) return model |
次に、探索するパラメータの範囲を決定します。
今回主に使う関数は下記の4点です。
| 関数名 | 対象の型 | 説明 |
| suggest_int | int型 | 指定した範囲の実数値の最適値を探索(実数値) |
| suggest_uniform | float型 など | 指定した範囲の最適値の最適地を探索(浮動小数点あり) |
| suggest_discrete_uniform | int,float型 など | 指定した範囲、間隔で最適値を探索(100~500の範囲を、100刻みで探索 など) |
| suggest_categorical | カテゴリ変数 | 指定したカテゴリ変数の最適値を探索(”sgd”, “adam”どっちが最適か など) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#パラメータ最適化部 def objective(trial): print("Optimize Start") #セッションのクリア keras.backend.clear_session() #畳込み層の数のパラメータ num_layer = trial.suggest_int("num_layer", 2, 5) #全結合層のノード数 mid_units = int(trial.suggest_discrete_uniform("mid_units", 100, 300, 100)) #各畳込み層のフィルタ数 num_filters = [int(trial.suggest_discrete_uniform("num_filter_"+str(i), 16, 128, 16)) for i in range(num_layer)] #Dropout率 dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 0.5) #optimizer optimizer = trial.suggest_categorical("optimizer", ["sgd", "adam"]) model = create_model(num_layer, mid_units, num_filters,dropout_rate) model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]) history = model.fit(X_train2, y_train2, verbose=0, epochs=20, batch_size=128, validation_split=0.1) scores = model.evaluate(X_train2, y_train2) print('accuracy={}'.format(*scores)) #検証用データに対する正答率が最大となるハイパーパラメータを求める return 1 - history.history["val_accuracy"][-1] |
これで最適化の準備完了です。
最適化
最適化をする際は、「create_study」を利用してstudyオブジェクトを生成、「optimize」関数で最適化を実行の2STEPを踏む必要があります。
最適化は指定した範囲のパラメータをランダムに振ったモデルを、optimize関数の「n_traials」数だけ作成し、一番評価値が高かったパラメータを最適値とする。
という方法で実施されます。
|
1 2 3 4 |
# studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective, n_trials=30)#時短のため30回 |
30回の探索が終了したので、studyオブジェクトのbest_paramsを使って、選ばれたベストパラメータを確認していきます。
|
1 |
study.best_params |
|
1 2 3 4 5 6 7 8 9 10 |
#出力結果 {'num_layer ': 5, 'num_filter_0': 48.0, 'num_filter_1': 64.0, 'num_filter_2': 96.0, 'num_filter_3': 96.0, 'num_filter_4': 128.0, 'mid_units': 100.0, 'optimizer': 'sgd', 'dropout_rate' 0.4916904519518987 } |
上記が今回のベストパラメータでした。畳み込み層の層数(num_layer)が5になっています。前回のモデルは2層のCNNであったので、一番効いているパラメータである層数を適当に設定しまくったみたいです。
ちなみに上記の最適化をローカル環境で行ったところ、3時間くらいかけてもepochが2回しか回ってなかったので、GPU環境は必須です。
最適化モデル作成
最適化後のパラメータを利用して、新しいモデルを作成していきます。
コードは下記です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#最適paramterのセット num_filters = [48,64,96,96,128] mid_units= 100 dropout_rate = 0.4916904519518987 optimizer = 'sgd' #最適化後のモデル(畳み込み層5層のCNN) model_best = Sequential() model_best.add(Conv2D(filters=num_filters[0], kernel_size=(3, 3),activation="relu",input_shape=(img_rows, img_cols, 1))) model_best.add(Conv2D(filters=num_filters[1], kernel_size=(3,3), padding="same", activation="relu")) model_best.add(Conv2D(filters=num_filters[2], kernel_size=(3,3), padding="same", activation="relu")) model_best.add(Conv2D(filters=num_filters[3], kernel_size=(3,3), padding="same", activation="relu")) model_best.add(Conv2D(filters=num_filters[4], kernel_size=(3,3), padding="same", activation="relu")) model_best.add(MaxPooling2D(pool_size=(2, 2))) model_best.add(Dropout(dropout_rate)) model_best.add(Flatten()) model_best.add(Dense(mid_units)) model_best.add(Dropout(dropout_rate)) model_best.add(Dense(num_classes, activation='softmax')) #最適化手法などを決定 model_best.compile(loss=keras.losses.categorical_crossentropy, #optimizer=keras.optimizers.Adadelta(), optimizer=optimizer, metrics=['accuracy']) #本番データをreshape X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1) X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1) y_train = keras.utils.to_categorical(y_train, num_classes) #学習を開始 hist2 = model_best.fit(X_train, y_train, batch_size=128, epochs=20, validation_split=0.1, verbose=1) scores_best = model_best.evaluate(X_train, y_train) |
|
1 2 3 4 5 6 7 |
#出力結果 ・ ・ ・ ETA: 0s - loss: 0.0118 - accuracy: 0.99 - ETA: 0s - loss: 0.0119 - accuracy: 0.99 - 6s 4ms/step - loss: 0.0119 - accuracy: 0.9966 |
accuracyが0.9966(99.66%)でした。
ちなみに前回の記事のモデルも同等の精度でしたが、正直これ以上上がりにくいのでこんなもんかなと思います。
学習曲線
最後に過学習(overfitting)、学習不足(underfitting)を確認に学習曲線を図示してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#loss plt.plot(hist2.history['loss']) plt.plot(hist2.history['val_loss']) plt.title('model loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() #Accuracy plt.figure() plt.plot(hist2.history['accuracy']) plt.plot(hist2.history['val_accuracy']) plt.title('model accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper left') plt.show() |
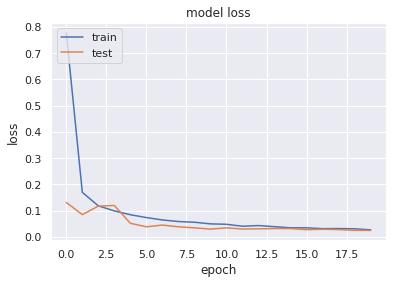
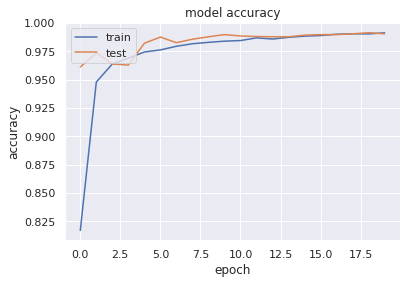
過学習などの傾向はみられませんでした。というよりもtrainデータとtestデータの精度がほとんど一致してるので、前回よりいい気がします。
提出
さあ、結果を確認しましょう。出力用のコードは前回の記事をまるパクリです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#テストデータの予測結果を出力(predeict_classes) y_pred = model_best.predict_classes(X_test_best) my_cnn = pd.DataFrame() imageid = [] for i in range(len(X_test_best)): imageid.append(i+1) my_cnn['ImageId'] = imageid my_cnn["label"] = y_pred my_cnn.to_csv("./cnn_optuna.csv", index=False) print('csv書き出し終了') |
提出結果
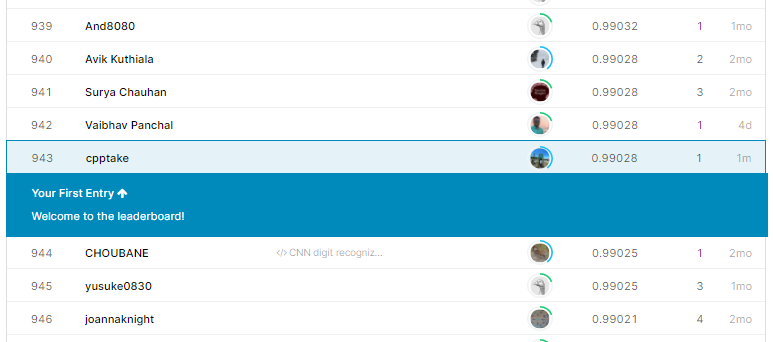
Score:99.028% 順位:943位/2335位中
以前作成したモデルと比較するこんな感じです。
| model | score |
| MLP(scikit-learn) | 0.95971 |
| CNN(Keras) | 0.98814 |
| CNN(Keras) with optuna | 0.99028 |
ちょっと精度上がった。
まとめ
機械学習のハイパーパラメータ最適化ツールoptunaを利用して、KerasのCNNモデルの精度が向上することを確認しました。
計算コストは膨大ですが、kaggleなどの精度が求められる分野では武器になりそうなので、今後も使っていきます。
関係ないけど
こんな記事見つけました。なんでCNNの記事書いた瞬間にこんなこと言うの。今度使お。

参考文献
ありがとうございます。



コメント