
概要
youtuberになってメントスコーラする仕事がしたかった。どうも、しぃたけです。
Webスクレイピングの勉強をしたくていろいろ調べていたら、youtubeのスクレイピングをする方法を発見したので、記事にしてみます。
これまでkaggleやデータサイエンスの記事が多めでしたが、現実では分析したいデータがそろっていることの方が稀です。データ活用人材を目指している人なら自分でデータを拾ってくるスキルもこれから必要になってくると思うので、データ関係に興味を持っておられる方も是非見ていただければと思います。
youtube data apiについて
何それ
その名の通り、youtubeのデータを取り出すためのAPIです。
ちなみにAPIの公式リファレンスは下記にありますが、全日本語対応しています。自分の苦手としている英訳が必要ないのでこれは非常に嬉しい。さすがGoogle、神過ぎる。

このAPIはPythonだけでなく、Java、Javascript、Go、Ruby、.NET、PHP などの多言語に対応しているのもうれしいところです。
何ができるか
検索結果、サムネイル画像、チャンネル登録者などの情報がいろいろ取ってこれますが、詳しくは公式リファレンス見てください。(投げやり)
使ってみた
早速使ってみます。
なお、youtube data apiの取得方法については下記の記事がわかりやすかったです。

また、開発環境はGoogle Colaboratoryを利用しています。理由はyoutube data apiをローカルで利用しようとすると、余計なライブラリをインポートする必要があるので、最初から環境が整ってるColabを使った方が手っ取り早いためです。
参考までに。
API叩いてみる
とりあえず使ってみます。
まずは、検索ワード「筋トレ」で検索した際の検索結果を取得するスクリプトを作成してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from apiclient.discovery import build from apiclient.errors import HttpError # API情報 DEVELOPER_KEY = 'APIキーを入力' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY ) #検索ワード:筋トレ で検索 search_response = youtube.search().list( q='筋トレ', part='id,snippet' ).execute() search_response |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
##出力結果 {'etag': '5_mkq1yXzfEUU6d6JkCyj9Xsm3c', 'items': [{'etag': 'HZcgwuscpwg5Vp6VyXGl7A2CO5c', 'id': {'kind': 'youtube#video', 'videoId': 'sM3W0b1PdOY'}, 'kind': 'youtube#searchResult', 'snippet': {'channelId': 'UCZWyZ5L_MVBCcB8vmkspb8A', 'channelTitle': 'メトロンブログ', 'description': 'パーソナルトレーナーを趣旨にしたBOOST° というチャンネルを始めました! 新しい腹筋メニューも豊富に行っていきますので興味のある方は是非チェックしてください!!', 'liveBroadcastContent': 'none', 'publishTime': '2018-05-16T09:32:13Z', 'publishedAt': '2018-05-16T09:32:13Z', 'thumbnails': {'default': {'height': 90, 'url': 'https://i.ytimg.com/vi/sM3W0b1PdOY/default.jpg', 'width': 120}, 'high': {'height': 360, 'url': 'https://i.ytimg.com/vi/sM3W0b1PdOY/hqdefault.jpg', 'width': 480}, 'medium': {'height': 180, 'url': 'https://i.ytimg.com/vi/sM3W0b1PdOY/mqdefault.jpg', 'width': 320}}, 'title': '短期集中型【1日2分だけ】週3日の耐久戦腹筋でお腹を割るトレーニング方法 Abs Training'}}, {'etag': 'QGoUnN8EfQVU5OfvgiaZJKIyAx4', 'id': {'kind': 'youtube#video', 'videoId': '6JIRtnZyqwA'}, 'kind': 'youtube#searchResult', 'snippet': {'channelId': 'UCZWyZ5L_MVBCcB8vmkspb8A', 'channelTitle': 'メトロンブログ', 'description': '【僕のオフィシャルサイト】是非遊びに来てください→ https://www.keithet.com/home 【メトロンブログの筋トレサイト】トレ知識が詰まった日本でも有数の筋トレWebサイト→ ...', ・ ・ ・ |
結果はPythonの辞書型で出力されます。
キーの部分にデータの内容が記載されており、チャンネル名、URL、動画タイトル などの情報が記載されてます。
ちなみに下記のように[‘items’]のプロパティを利用すると出力結果をリスト化できます。
|
1 2 3 |
#入力 #['items']で検索結果をリストで取得(データ数多いので出力結果は割愛 search_response['items'] |
[‘pageInfo’]プロパティを利用すると、のページング情報が取得できます。
|
1 2 |
#入力 search_response['pageInfo'] |
|
1 2 |
#出力結果 {'resultsPerPage': 5, 'totalResults': 1000000} |
プロパティの詳細はこちら。
取得データをpandas DataFrameに変換
最後に、データをpandasのDataFrame型に変換する方法を記します。
ちなみに、youtube data apiのデフォルトでは5件までしか動画の情報を取得できないので、こちらのqiitaの記事を参考に5件以上のデータ取得をできるようにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
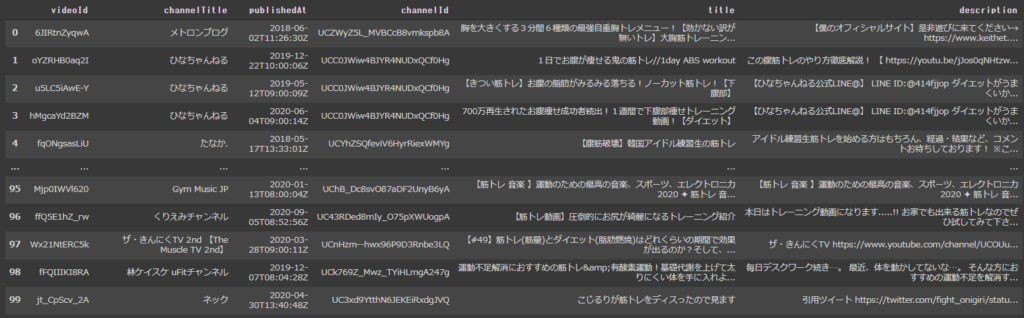
#入力 import pandas as pd #youtubeデータをpandasに変換する関数 def get_video_info(part, q, order, type, num): dic_list = [] search_response = youtube.search().list(part=part,q=q,order=order,type=type) output = youtube.search().list(part=part,q=q,order=order,type=type).execute() #デフォルトでは5件しか取得できないので、繰り返し取得 for i in range(num): dic_list = dic_list + output['items'] search_response = youtube.search().list_next(search_response, output) output = search_response.execute() df = pd.DataFrame(dic_list) #各動画毎に一意のvideoIdを取得 df1 = pd.DataFrame(list(df['id']))['videoId'] #各動画毎に一意のvideoIdを取得必要な動画情報だけ取得 df2 = pd.DataFrame(list(df['snippet']))[['channelTitle','publishedAt','channelId','title','description']] ddf = pd.concat([df1,df2], axis = 1) return ddf #キーワード筋トレでデータを20回×5件取得 df_out = get_video_info(part='snippet',q='筋トレ',order='viewCount',type='video',num = 20) df_out |
ちなみに、動画再生回数、高評価、低評価数などを取得する方法は下記の通りです。詳細は参考文献をどうぞ。
|
1 2 3 4 5 6 7 8 9 |
# def get_statistics(id): statistics = youtube.videos().list(part = 'statistics', id = id).execute()['items'][0]['statistics'] return statistics df_static = pd.DataFrame(list(df_out['videoId'].apply(lambda x : get_statistics(x)))) df_output = pd.concat([df_out,df_static], axis = 1) df_output |
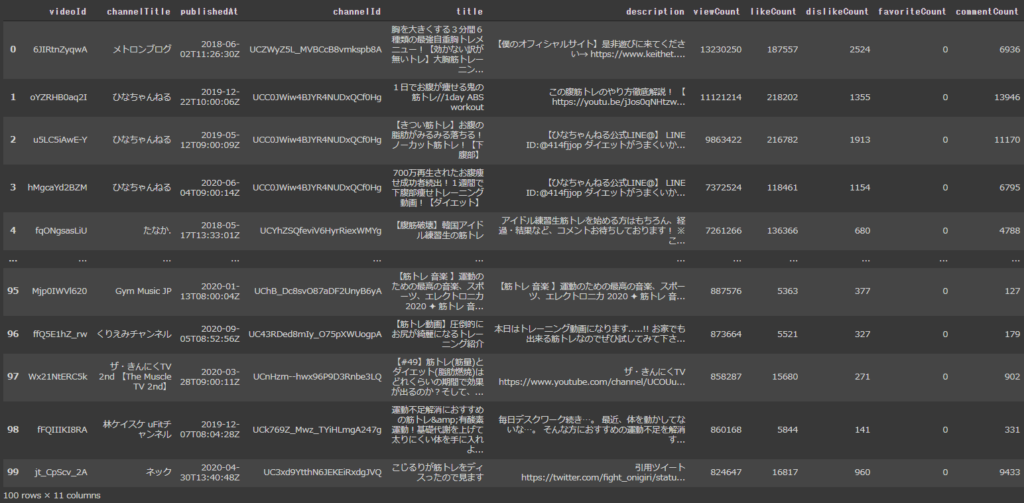
これだけデータ取れれば、データ分析、モデル作成にも利用できそうですね。
youtube data api利用の際の注意点
apiを利用していると、下記のようなエラーが発生しました。
|
1 2 |
##エラー内容 HttpError: <HttpError 403 when requesting https://youtube.googleapis.com/youtube/v3/search?part=snippet&q=%E7%AD%8B%E3%83%88%E3%83%AC&order=viewCount&type=video&key=AIzaSyDqPUq7GAaH-bzRwezlSygsr4XsM-cZ1RQ&alt=json&pageToken=CBQQAA returned "The request cannot be completed because you have exceeded your <a href="/youtube/v3/getting-started#quota">quota</a>."> |
どうやら、youtube data apiは利用限度数が決まっているそうで、限度回数以上apiを叩いてしまうとこのようなエラーが発生するそうです。
数日でまた使えるようになるみたいですが、ご利用の際は注意ください。
まとめ
Python のyoutube data apiを使ってスクレイピングを行う基礎をまとめました。
なによりGoogleの公式リファレンスが充実していて使いやすかったので、自分みたいなスクレイピング初心者でも簡単に実装できると思います。
時間があったら、取得したデータをDBに保存するような機能を実装したいと思います。
参考文献




コメント